
每天认识一个NLP经典模型-从N-gram到NNLM
为什么开这个系列
现在NLP的课程已经多的不能再多了,LLM出来之后,似乎Transformer,GPT也成为了每个人都要学习的一个东西,LLM已经成为了划时代的里程碑这点毋庸置疑。刚好上学期上了NLP的课,也认真听了几节,最近也在看一个开源项目用到了GPT2,然后想,诶诶诶我好些Transformer,BERT这些不太熟欸(怪不得MLSys里面的QKV也看不懂),所以决定趁着一些知识还没忘,重新拿出来复习一下,也编一编代码,增强对模型的理解。所以模型就从N-gram到BERT,GPT2就行了。
经典统计模型
在很久很久以前,一群研究自然语言的计算机科学家们在解决一些难题。比如:
- 给定一个句子,判断这个句子下一个词是什么
- 给定一个句子,判断这个句子下一个词的词性
怎么解决这些问题?现在已经知道,可以用DL来训练网络,但在当时电脑内存都只有几十几百MB的时代,这肯定是不现实的,所以一个很合理的方案就出来了:统计。
(实际上NLP统计模型有很多,我这里精简了,只讲讲N-gram)
为了解决上面的一些问题,NLPer搬出了概率统计里面一个经典公式,条件概率。
给定一个话比如我喜欢吃+苹果/李子/草莓
那么
$$
p(我喜欢吃苹果)=p(我喜欢吃) \cdot p(苹果|我喜欢吃)
$$
$$
p(x_1, x_2, \dots, x_n) = p(x_1) \cdot p(x_2 | x_1) \cdot p(x_3 | x_1, x_2) \cdot \dots \cdot p(x_n | x_1, x_2, \dots, x_{n-1})
$$
这里理解是说出一句话是有顺序的,那么完全可以统计任意情况下某些词出现的频率,比如(我,喜欢),(我,草莓)出现的频率,而且你可以任意统计,但因为计算能力限制和实际效果验证,一般取3-4的为一组,即3-gram,4-gram
这样,在统计出所以数据后,当你给出这样一个句子时:
你好,你吃饭__?
模型会根据之前数据集里面统计好的(你好,你,吃饭)的频率和(你好,你,吃饭,X)的频率,取max(frequency(你好,你,吃饭,X)),则X就是预测的下一个词。因为它的条件概率最大。
N-gram
那现在我要用神经网络呢?->NNLM
那虽然4-gram在当时已经很高级了,有没有用神经网络在建模语言的方法呢?给神经网络输入一段句子,给我输出下一个词。当然可以。
要想在神经网络里训练,首先要把数据换一下格式,可以用one-hot独热编码,也可以用编号索引。
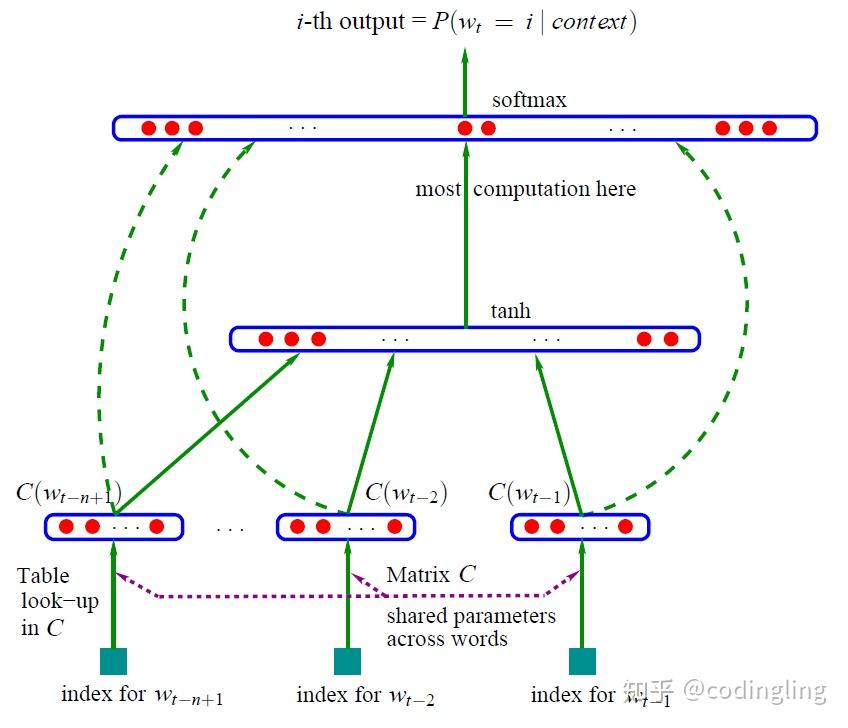
NNLM通过embedding将不同batch的向量映射成稠密向量,通过tanh经过一层隐藏层后,在输出层在正向运算的向量与展平后的嵌入向量,即C(w_i)拼接,通过线性层变换,两者形状均为(batch_size,n_class)。便是每个batch的预测结果


