
每天认识一个NLP经典模型-从Word2Vec到CBOW,Skip-Gram
横空出世->Word2Vec
Word2Vec最重要的贡献就是将词用向量表征出来,并且发现了向量计算之间的语义关系,比如
$$
man - woman = king - queen
$$
这在当时是很有意思的研究,但值得注意,word2vec并不是第一个提出词向量思想的模型,回顾上一篇提到的nnlm,在实现的时候会发现会用到embedding,这是nnlm为了将离散的词转到连续的向量空间中便于计算,从而获得预测词的概率分布。Word2Vec 的 embedding 是通过 CBOW 或 Skip-Gram 模型训练得到的,专注于捕捉词汇之间的语义关系,而不是直接服务于语言建模任务。这也是为什么它伟大,在此之前,embedding只是为了语言建模的工具而已,而word2vec让这层embedding有了语言学的意义。
两种实现:CBOW 与Skip-Gram
区别在于数据集的构造,对于(x,y)的数据集: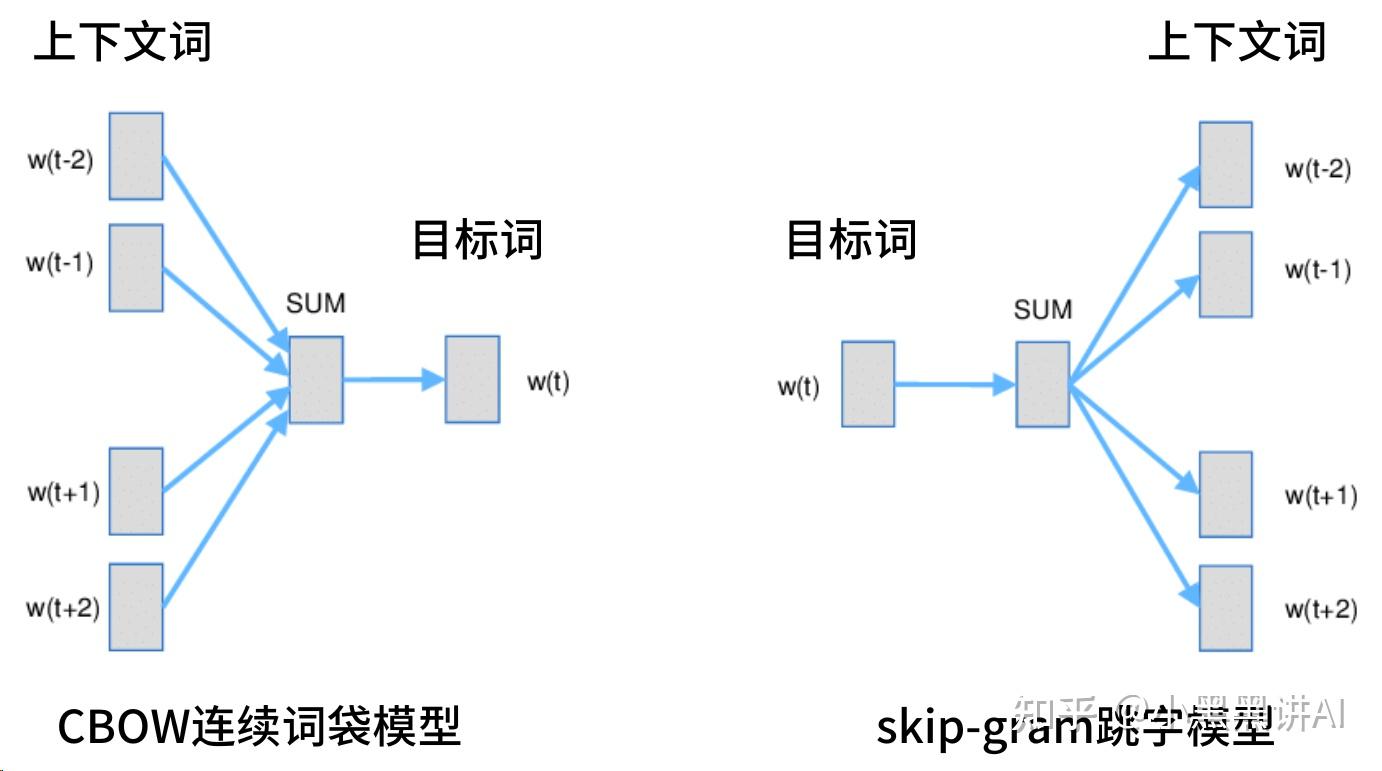
CBOW尝试构造context->target映射,融合多个context(sum)训练,epoch也会少一些
Skip-Gram尝试构造target->context映射,单个target对于多个context,epoch多一些
- CBOW的implement还可以改改:提供windows-size定制
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 Melo's Blog


