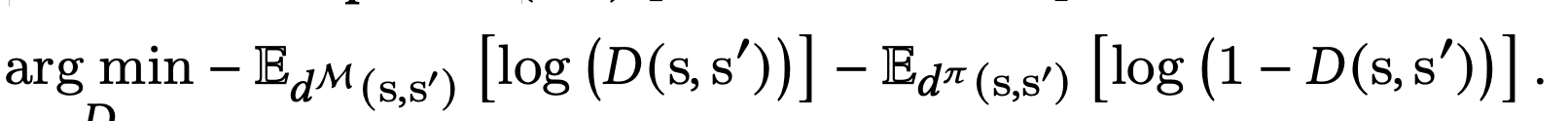从DeepMimic出发,让仿真中的人能像“人”一样 本次DateWhale基于的论文是CooHOI ,整个项目框架大概为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 ├── coohoi/ # 主代码目录 ├── run.py # 主入口:启动训练/测试,集成RL-Games框架 ├── learning/ # 训练学习模块 │ ├── common_agent.py # 通用智能体基类(策略/价值网络训练,PPO算法实现) │ ├── common_player.py # 通用玩家基类(推理和评估逻辑) │ ├── amp_agent.py # AMP智能体(对抗运动先验训练,判别器优化) │ ├── amp_players.py # AMP玩家实现(支持运动风格化推理) │ ├── amp_models.py # AMP连续模型定义(策略网络结构) │ ├── amp_network_builder.py # AMP神经网络构建器(创建判别器和策略网络) │ ├── amp_datasets.py # AMP数据集处理(加载和管理运动数据) │ └── replay_buffer.py # 经验回放缓存(存储训练样本,支持AMP) │ └── legacy.py # 向后兼容代码 ├── env/ # 环境定义 │ └── tasks/ # 任务实现 │ ├── vec_task.py # 向量化任务基类(CPU/GPU加速) │ ├── vec_task_wrappers.py # 环境包装器(支持不同后端) │ ├── base_task.py # 基础任务类(定义RL环境接口) │ ├── humanoid.py # 基础人形机器人环境(核心物理模拟) │ ├── humanoid_amp.py # 支持AMP的人形环境(加入运动先验) │ ├── humanoid_amp_carryobject.py # 单智能体搬运物体任务(拾取+搬运+放置) │ ├── humanoid_amp_task.py # 单智能体任务配置包装器 │ ├── humanoid_view_motion.py # 运动可视化环境(调试工具) │ ├── share_humanoid.py # 双人协作环境(两个机器人交互) │ ├── share_humanoid_amp.py # 双人AMP环境 │ └── share_humanoid_amp_carryobject.py # 双智能体协作搬运任务(合作搬运) ├── utils/ # 工具函数库 │ ├── config.py # 配置解析器(管理命令行参数和配置文件) │ ├── parse_task.py # 任务工厂(动态创建任务实例) │ ├── motion_lib.py # 运动库管理器(加载AMASS运动数据) │ ├── torch_utils.py # PyTorch工具函数(3D旋转、几何变换) │ ├── gym_util.py # Gym环境工具函数 │ └── logger.py # 日志记录工具 │ └── __init__.py # 模块初始化 ├── poselib/ # 姿势与运动处理库 │ ├── retarget_motion.py # 运动重定向(适配不同骨骼结构) │ ├── fbx_importer.py # FBX格式导入器 │ ├── mjcf_importer.py # MJCF格式导入器 │ ├── generate_amp_humanoid_tpose.py # 生成标准T-Pose姿态 │ └── poselib/ # 核心姿势库 │ ├── core/ # 核心数学功能 │ │ ├── rotation3d.py # 3D旋转计算(欧拉角、四元数、旋转矩阵) │ │ └── tensor_utils.py # 张量操作工具函数 │ ├── skeleton/ # 骨骼系统 │ │ └── skeleton3d.py # 3D骨骼定义与操作 │ └── visualization/ # 可视化工具 │ ├── core.py # 可视化核心功能 │ ├── plt_plotter.py # Matplotlib绘图器 │ └── skeleton_plotter_tasks.py # 骨骼可视化任务 └── data/ # 数据资源目录 ├── assets/mjcf/ # 模型定义文件 │ ├── amp_humanoid.xml # 人形机器人MJCF定义 │ ├── box.urdf # 箱子模型 │ └── *.urdf # 其他物体模型 ├── cfg/ # 配置文件 │ ├── train/ # 训练配置 │ │ ├── amp_humanoid_task.yaml # 单智能体训练配置 │ │ └── share_humanoid_task_coohoi.yaml # 双智能体训练配置 │ ├── humanoid_carrybox.yaml # 单智能体环境配置 │ └── share_humanoid_carrybox.yaml # 双智能体环境配置 ├── models/ # 预训练模型 │ ├── SingleAgent.pth # 单智能体策略权重 │ └── TwoAgent.pth # 双智能体协作策略权重 ├── motions/ # 运动数据集 │ ├── amp_original/ # 原始AMP运动数据(行走、跑步) │ └── coohoi_data/ # CooHOI扩展数据 │ ├── coohoi_data.yaml # 运动数据配置 │ ├── loco/ # 行走数据 │ ├── loco_reverse/ # 倒序行走数据 │ ├── pickup/ # 拾取动作 │ ├── carry/ # 搬运动作 │ ├── carry_reverse/ # 倒序搬运 │ ├── putdown/ # 放置动作 │ └── sidewalk/ # 特定场景行走 └── objects_asset/ # 物体资产(可选)
CooHOI基本是沿用了AMP/ASE(都是Jason Xue Bin Peng的文章)的代码框架,主要添加了learning和model里对协同任务的定义和支持,以及对应assert的加载,包括run.py来控制整个项目训练与评估,可视化。
其实有很多的项目都沿用了AMP当中的模块,包括CMU LecarLab的H2O 、Zen Luo的通用人型控制器PHC ,包括Jason Peng后续的ASE,MimicKit。
Mimic作为一个Unified Reward 在DRL刚开始被大家开始做的时候,一些比较有代表性的工作比如AlphaGo(几乎没有人类可以打败),虽然通过大量的episode训练,但是其实reward设计是非常复杂的。这在Avatar Motion方面也是如此,当时做动画动作生成,一般都是使用Dynamics Model,就跟对某一个任务的reward设计一样,这些model用来设计一些特定的动作,比如奔跑,翻转等。但是如果需要新加动作就需要新的模型来支持,这是非常耗费人力的。所以DeepMimic的思路就是,虽然我做每个动作的reward function都是不同的,但是对于motion tracking来说,我只需要保证agent在每个时刻与我们所期待的动作(也就是类似人类的动作)一致,那么我们可以将reward设计成一个unified reward function,reward就根据当前agent各个关节位置与输入指导数据(一般是动作捕捉数据)之间的差异来计算,这样不仅各个动作的function可以统一而且这样可以避免一些sparse reward,然后通过训练这个reward function来学习agent所期待的动作。
AMP将单纯的动作数值误差转为分布的误差 其中GAN中descriminator的loss定义为数据集中状态转移对上,D函数将状态转移变为一个概率分布,通过loss来约束使得两者分布接近。同时reward也做了处理来让policy输出的状态转移分布更接近真实数据集的分数
CooHOI 优化Cooperative Humanoid Task 相对于AMP,CooHOI的MDP可以看做的是Partial Observation。其实每个agent的observation是local而不是全局的,所以在后面多agent任务的时候,作者优化了agent的local observation,使得agent更关注自己搬运物体的一角。还有一点CooHOI divide training into two-phase,先是基于AMP训练一个单agent完成定义好的task的策略,之后基于这个策略进行多agent任务训练。因为是POMDP,所以每个agent都可以用这个policy来与环境交互,同时可以从多agent得到梯度回传,用MAPPO进行梯度优化。
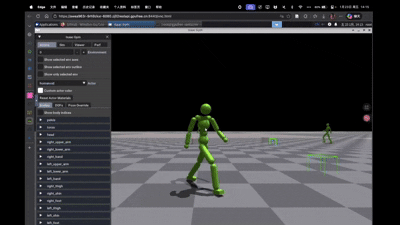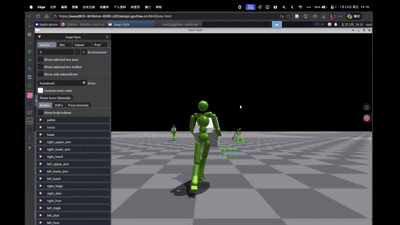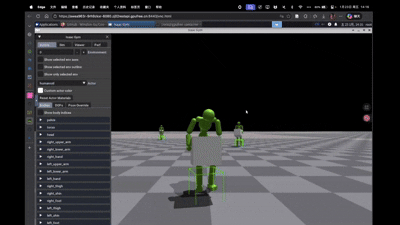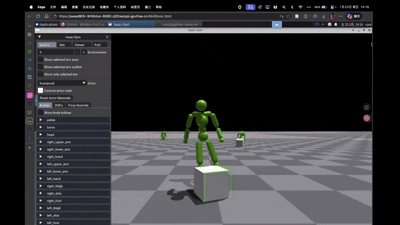
评估 单agent
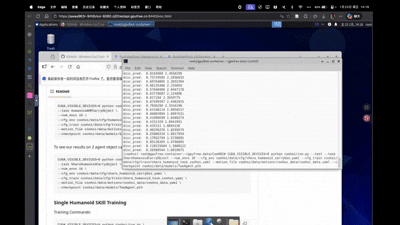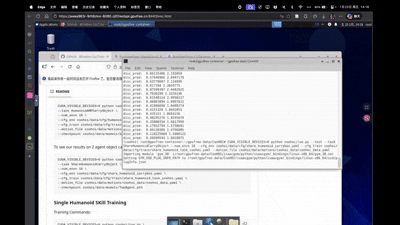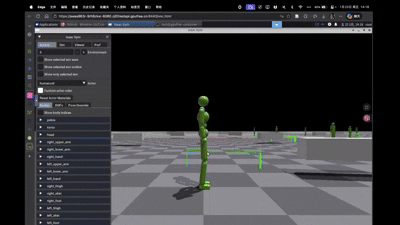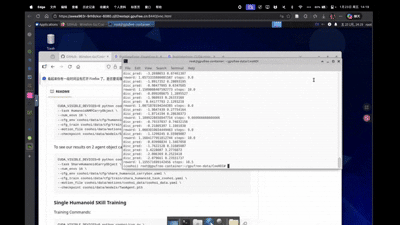
1 2 3 4 5 6 CUDA_VISIBLE_DEVICES=0 python coohoi/run.py --test \ --task ShareHumanoidCarryObject \ --num_envs 16 \ --cfg_env coohoi/data/cfg/share_humanoid_carrybox.yaml \ --cfg_train coohoi/data/cfg/train/share_humanoid_task_coohoi.yaml \ --motion_file coohoi/data/motions/coohoi_data/coohoi_data.yaml \
训练 我们这里主要从Scratch开始训练,由于算力和训练时长只训练一个Single Agent策略,并且这里遇到了涉及到wandb的断点续训以及API_KEY的一些bug,后面我会继续写个blog来介绍怎么做